Продолжаем. "Глубокое исследование" в GPT. (Deep Research).
💟 Не пугайтесь сладкие, много букв, но упрощаю уже как могу)
Если обычный чат GPT - это просто «вкинул запрос → получил ответ» (в рамках тех же 4k токенов, помним, да?), то глубокое исследование - это уже режим детектива.
Глубокое исследование, позволяет собрать всю информацию, что у вас есть или найти самостоятельно, чтобы упаковать все знания в один файл.
Далее этот файл можно использовать обратно в GPT, чтобы он понимал контекст нужных знаний.
К примеру, чтобы писать ахуительные посты, можно создать файл с нужной ЦА и при каждом создании поста, GPT будет знать на кого ориентируемся, если мы скормим ему этот файл.
А что если тебе нужно раскопать и проанализировать дохрена имеющихся данных, файлов, таблиц, книг, PDF, экселек и другой инфы?
Тут простой GPT не вывезет. Точнее даже вывезет, но вам придется собирать все ручками.
Если обычный GPT просто угадывает следующее слово, то в режиме Deep Research:
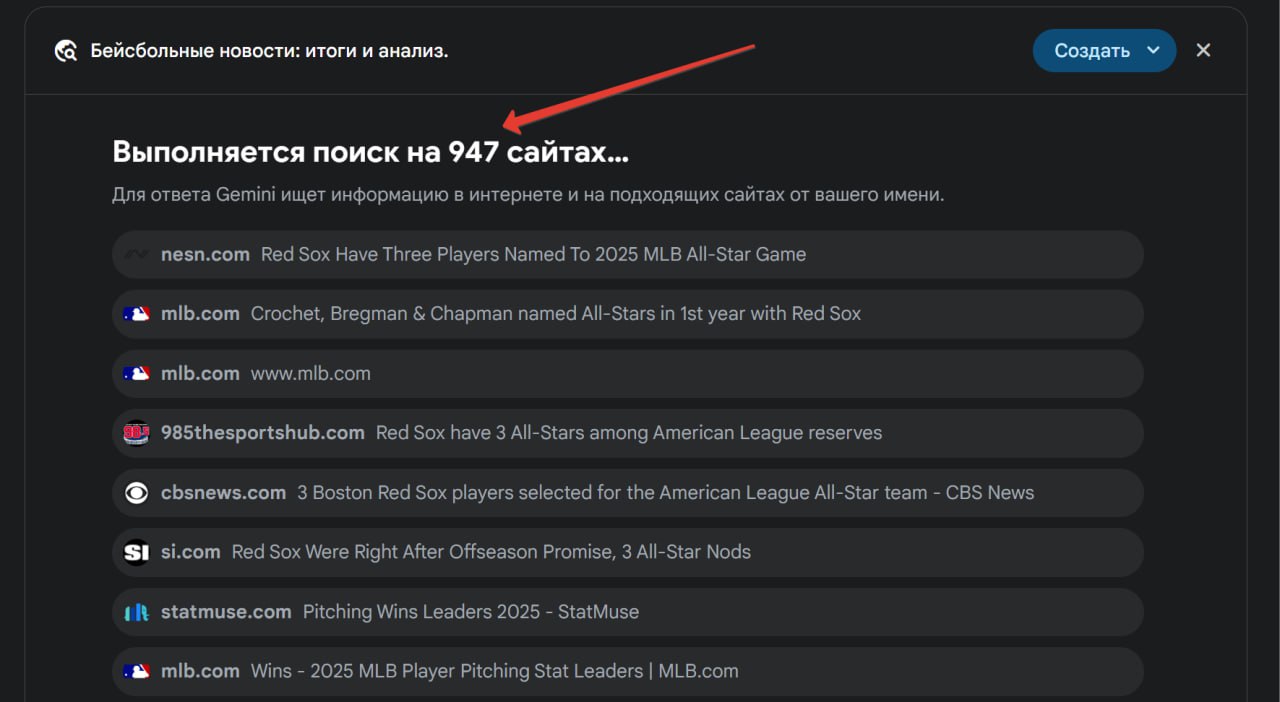
🔎 Сначала разбивает твой запрос на подзадачи.
🌐 Потом лезет в интернет, проверяет статьи, документацию, форумы, которые подходят под твой запрос.
📂 Анализирует все файлы, которые ты ему подсунул (PDF, Excel, .md-файлы и картинки).
👾 Вспоминает всё, о чём ты писал в этой же сессии.
✍️ В конце сводит это в понятный структурный вывод, который обязательно НУЖНО ПЕРЕЧИТАТЬ. ПЕРВОЕ ПРАВИЛО GPT - НЕ ВЕРЬ GPT. Все перепроверяйте, плиз.
Чё по ограничениям?
- Первые 1-3 запроса ГИ* дают максимально чёткие ответы.
- На 5–7 запросе уже начинаются повторы, текст становится водянистым.
- После 10 шага GPT тупо начинает генерировать маленький кусок высера, чтобы заполнить токены.
Поэтому тут, лучше подходить с умом.
🪙 А чё по токенам?
В Deep Research лимит ответа увеличивается: уже не 4k, а до 8k или даже 16k токенов (в зависимости от кол. оставшихся запросов).
НО! Это только длина ответа. Твои входные данные всё ещё ограничены контекстом в 128k токенов.
Так что заливать туда полностью "Войну и Мир" - по-прежнему плохая идея.
В этом режиме меньше галлюцинаций - GPT старается не придумывать от себя, а чаще цитирует источники.
🔗 ГИ Склеивает файлы + интернет + чат в единый вывод, который уже готовый под вставку в тот же Obsidian. Тебе остаётся тупо скопировать.
GPT будет тебе задавать уточняющие вопросы после запроса, когда ты нажмёшь глубокое исследование.
И тут главное не забить БОЛТ, как многие делают, а заранее попросить у него как можно больше вопросов, чтобы он лучше понял ваш запрос.
*ГИ - Глубокое исследование
#СразбегавGPT